|
Jingjing Zheng (郑晶晶) "Theory without practice is empty, but equally, practice without theory is blind." — I. Kant Hello! I'm Jingjing Zheng (she/her), a Ph.D. student in Mathematics at the University of British Columbia, supervised by Prof. Yankai Cao. My research interests include efficient training/inference of large models grounded in theory, low-rank/tensor methods, and sparse representation learning. My academic background spans art and design (B.A.), mathematics (M.S. and current Ph.D.), and computer science (completed Ph.D. degree). I received the Borealis AI Fellowship (awarded to ten AI researchers across Canada) and the Government Award for Outstanding Self-financed Students Abroad (awarded to 650 outstanding young talents worldwide). 🌈 I am committed to supporting LGBTQ+ visibility, inclusion, and diversity within academia and STEM communities. |

|
| News Research Experience Awards Community Service Presentations Teaching |
Recent News[2026] This summer, I will have a short-term visit to Prof. Qibin Zhao's group at RIKEN.
[2026] One paper accepted to CVPR 2026 (see you in Denver!).
[2025] Joined the Organizing Committee of Women and Gender-diverse Mathematicians at UBC (WGM).
[2025–2026] Appointed to the UBC Green College Academic Committee.
[2025] Our startup GradientX was selected for the Lab2Market Validate Program (Funded).
[2025] Two papers accepted to NeurIPS 2025 (see you in San Diego!).
|
Selected ResearchMy research focuses on efficient training/inference of large models, low-rank/sparse representation learning, and tensor optimization. For the full list, please visit Google Scholar. * corresponding author † supervisor |
|
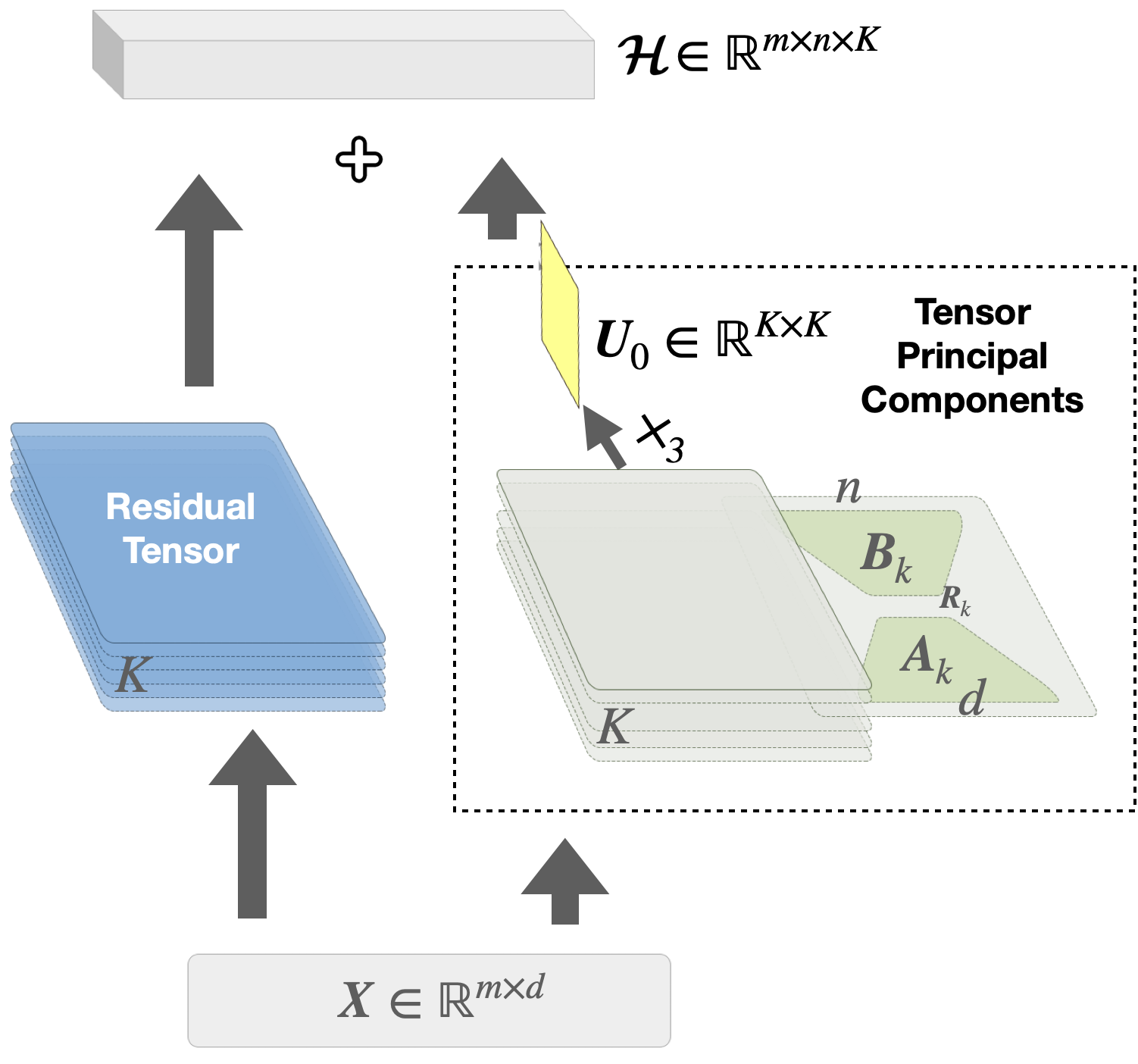
ReFTA: Breaking the Weight Reconstruction Bottleneck in Tensorized Parameter-Efficient Fine-Tuning
Jingjing Zheng, Anda Tang, Qiangqiang Mao, Zhouchen Lin*, Yankai Cao*,† CVPR, 2026 Breaks the weight reconstruction bottleneck in tensorized parameter-efficient fine-tuning for large models. Tensorized PEFT methods represent weight updates in compact tensor formats for high parameter efficiency, but incur significant overhead at inference due to weight reconstruction. ReFTA proposes a reconstruction-free tensorized adaptation framework that eliminates this bottleneck, achieving both parameter efficiency during fine-tuning and computational efficiency at inference, with strong performance on vision and language benchmarks. |
|
arXiv 2026
|
On Catastrophic Forgetting in Low-Rank Decomposition-Based Parameter-Efficient Fine-Tuning
Muhammad Ahmad, Jingjing Zheng, Yankai Cao*,† arXiv:2603.09684, 2026 paper Investigates catastrophic forgetting in low-rank decomposition-based PEFT methods and proposes mitigation strategies for continual adaptation of large models. Low-rank decomposition-based PEFT methods such as LoRA are widely adopted for efficient adaptation, but exhibit catastrophic forgetting in continual learning settings. This paper systematically studies the forgetting phenomenon across representative low-rank PEFT methods, identifies its root causes in the low-rank constraint, and proposes mitigation strategies that preserve prior knowledge while enabling effective sequential adaptation of large pre-trained models. |
|
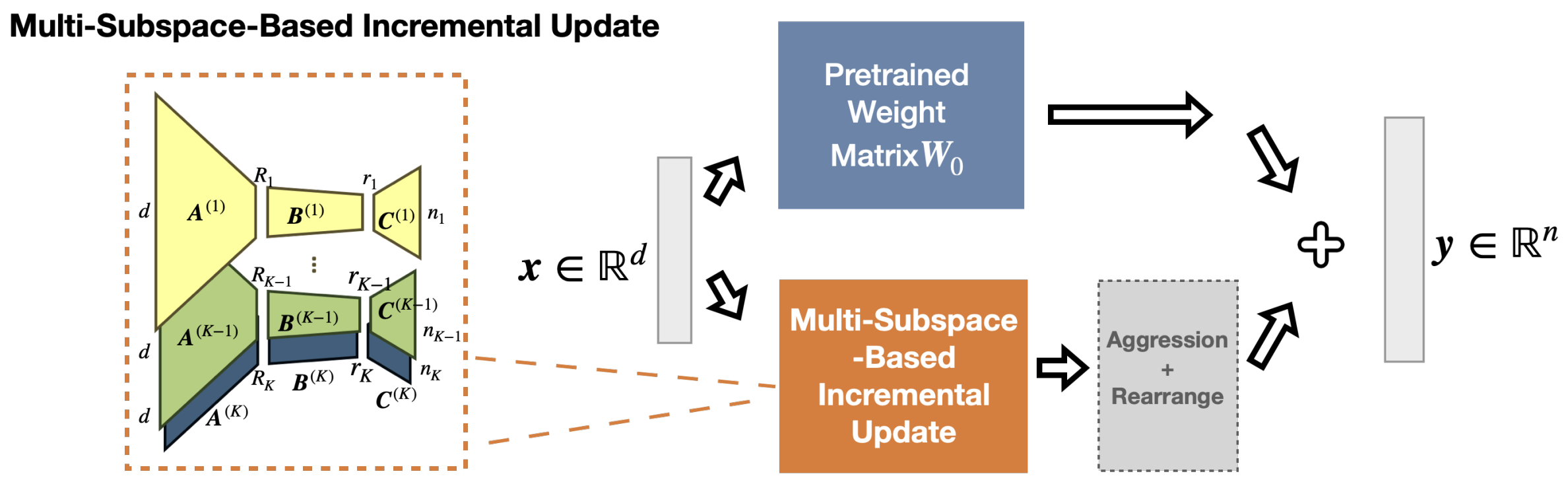
AdaMSS: Adaptive Multi-Subspace Approach for Parameter-Efficient Fine-Tuning
Jingjing Zheng, Wanglong Lu, Yiming Dong, Chaojie Ji, Yankai Cao*,†, Zhouchen Lin* NeurIPS, 2025 paper Leverages subspace segmentation to adaptively reduce trainable parameters, achieving better generalization than LoRA/PiSSA while using far fewer parameters. AdaMSS proposes an adaptive multi-subspace approach for parameter-efficient fine-tuning of large models. Unlike traditional PEFT methods that operate in a single large subspace, AdaMSS applies subspace segmentation to obtain multiple smaller subspaces and adaptively reduces trainable parameters during training, ultimately updating only those associated with the subspaces most relevant to the target task. Theoretical analyses show better generalization guarantees than LoRA and PiSSA. On ViT-Large, AdaMSS achieves 4.7% higher average accuracy than LoRA across seven tasks using only 15.4% of LoRA’s trainable parameters. On RoBERTa-Large, it outperforms PiSSA by 7% in average accuracy across six tasks while reducing trainable parameters by ~94.4%. |
|
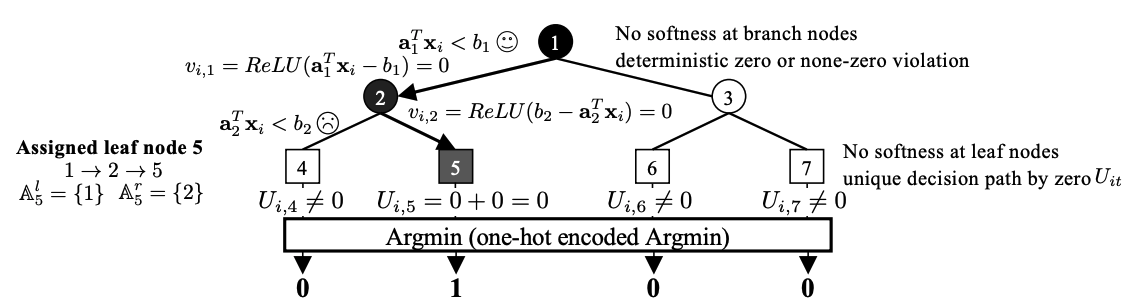
Differentiable Decision Tree via “ReLU+Argmin” Reformulation
Qiangqiang Mao, Jiayang Ren, Yixiu Wang, Chenxuanyin Zou, Jingjing Zheng, Yankai Cao*,† NeurIPS, 2025 (Spotlight) paper Proposes a differentiable decision tree reformulation using ReLU+Argmin for end-to-end training. Decision trees are inherently non-differentiable due to hard branching decisions at each node, preventing end-to-end gradient-based training. This paper introduces a “ReLU+Argmin” reformulation that makes the entire tree fully differentiable, enabling joint optimization with neural network components via standard backpropagation. The approach achieves strong performance on tabular data benchmarks while preserving the interpretability of tree-structured models. |
|
arXiv 2024
|
Adaptive Principal Components Allocation with the ℓ2,g-regularized Gaussian Graphical Model for Efficient Fine-Tuning Large Models
Jingjing Zheng, Yankai Cao*,† arXiv:2412.08592, 2024 paper Proposes adaptive principal component allocation guided by an ℓ2,g-regularized Gaussian graphical model to improve efficiency in fine-tuning large language models. Standard PEFT methods assign equal rank to all layers, wasting capacity on already well-adapted layers and under-fitting others. This work models inter-layer dependencies of weight matrices using an ℓ2,g-regularized Gaussian graphical model and uses the inferred structure to guide adaptive principal component allocation across layers, achieving better efficiency-accuracy trade-offs in fine-tuning large language models. |
|
Handling The Non-Smooth Challenge in Tensor SVD: A Multi-Objective Tensor Recovery Framework
Jingjing Zheng, Wanglong Lu, Wenzhe Wang, Yankai Cao*,†, Xiaoqin Zhang†, Xianta Jiang† ECCV, 2024 paper Addresses non-smooth tensor data recovery via a learnable tensor nuclear norm and the proposed APMM optimization algorithm with KKT convergence guarantees. Tensor SVD (t-SVD)-based recovery methods show strong results on visual data such as color images and videos, but suffer severe performance degradation when tensor data exhibits non-smooth changes—a common real-world phenomenon largely ignored by prior work. This paper introduces a novel tensor recovery model with a learnable tensor nuclear norm to address this challenge, and develops the Alternating Proximal Multiplier Method (APMM) to iteratively solve the proposed model. Theoretical analysis proves convergence of APMM to the KKT point of the optimization problem. A multi-objective tensor recovery framework is further proposed based on APMM to efficiently exploit correlations across tensor dimensions, extending t-SVD-based methods to higher-order tensor cases. Numerical experiments on tensor completion demonstrate the effectiveness of the approach. |

|
Bayesian-Driven Learning of A New Weighted Tensor Norm for Tensor Recovery
Jingjing Zheng, Yankai Cao*,† ICLR, 2024 (Tiny Papers Track) paper / code Learns a data-dependent weighted tensor norm via Bayesian Optimization within a bilevel tensor completion framework, addressing non-smooth changes and imbalanced low-rankness. t-SVD-based tensor recovery methods suffer from performance limitations caused by non-smooth changes and imbalanced low-rankness in tensor data. This work introduces a novel bilevel tensor completion model that integrates the learning of a data-dependent weighted tensor norm as an upper-level problem within the tensor completion framework. The bilevel optimization is treated as a black-box problem, and Bayesian Optimization (BO) is employed for efficient learning of the proposed tensor norm. Numerical experiments demonstrate superior performance compared to state-of-the-art tensor completion methods. |
|
Structured Sparsity Optimization with Non-Convex Surrogates of ℓ2,0-Norm: A Unified Algorithmic Framework
Xiaoqin Zhang*,†, Jingjing Zheng, Di Wang, Guiying Tang, Zhengyuan Zhou, Zhouchen Lin IEEE TPAMI, 2023 (IF: 20.8) paper / code A unified algorithmic framework for structured sparsity optimization with non-convex surrogates. Enforcing structured group sparsity—crucial for network pruning and feature selection—requires minimizing the ℓ2,0-norm, which is NP-hard. This paper proposes a unified framework using non-convex surrogate functions, deriving a family of proximal algorithms with global convergence guarantees. The framework subsumes several prior methods as special cases and achieves better sparsity-accuracy trade-offs on diverse tasks including neural network compression and multi-task learning. |
|
IEEE TNNLS 2022
|
Tensor Recovery With Weighted Tensor Average Rank
Xiaoqin Zhang*,†, Jingjing Zheng, Li Zhao, Zhengyuan Zhou, Zhouchen Lin IEEE Transactions on Neural Networks and Learning Systems, 2022 (IF: 11.1) paper / code Proposes Weighted Tensor Average Rank (WTAR) to capture relationships between differently-transposed tensors, with convex/non-convex surrogates and GTSVT solver for robust tensor recovery. This paper investigates a curious phenomenon in tensor recovery: do different transpose operations on observation tensors yield identical recovered results? If not, information within the data may be lost under certain transpose operators. To address this, a new tensor rank called Weighted Tensor Average Rank (WTAR) is proposed to learn relationships between tensors obtained via a series of transpose operators. WTAR is applied to three-order tensor robust PCA (TRPCA) to validate its effectiveness. To balance effectiveness and solvability, both convex and non-convex surrogates of the model are studied, with corresponding worst-case error bounds derived. A generalized tensor singular value thresholding (GTSVT) method and an associated optimization algorithm are proposed to efficiently solve the generalized model. |
|
AAAI 2022
|
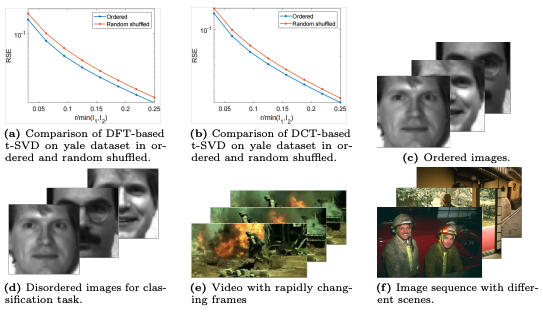
Handling Slice Permutations Variability in Tensor Recovery
Jingjing Zheng, Xiaoqin Zhang*,†, Wenzhe Wang, Xianta Jiang† AAAI, 2022 paper / supp / video / poster Addresses slice permutation variability in tensor recovery with a novel optimization approach. Tensor SVD (t-SVD) based recovery methods are sensitive to the ordering of frontal slices, yet this variability is rarely addressed in practice. This paper analyzes how slice permutations affect the t-SVD rank structure and recovery quality, and proposes an optimization framework that jointly estimates the latent tensor and its optimal slice ordering. Experiments on hyperspectral image recovery and video completion demonstrate consistent improvements by accounting for slice permutation variability. |
Experience
|
Selected Awards & GrantsAwards & Honors
Grants
|
Community Service
|
Presentations
|
TeachingTeaching Assistant
|
|
Design and source code from Jon Barron's website. |